Hadoop – Hive 성능 테스트 및 튜닝
Hadoop – Hive 성능 테스트 및 튜닝
| Hadoop 2012/05/25 16:35
근래에 진행 중이던 프로젝트에서 Hadoop + Hive로 시스템을 구성 한 후 간단한 성능 테스트와 튜닝 후기를 공유합니다.
기본 적인 설치는 이전 포스팅 Cloudera CDH 패키지를 이용한 Hadoop 설치 하기 와 Cloudera CDH 패키지를 이용한 Hive 설치 하기 를 참조하시고 본 블로그에 나오는 성능 지수는 공식적인 성능 수치와는 하등 관계가 없다는 것을 명심하시기 바랍니다 ^^
1. 테스트 환경
– 시스템 환경 : Intel Xeon 2.27GHz 16 Core CPU, 32G Memory
– 데이터 환경 : 1 Row가 약 527Byte인 Test Data를 Text File로 HDFS에 저장하여 테스트
– 테스트 방식 : HDFS에 Log FIle을 직접 저장 한 후 Hive External Table로 설정하여 Select Test
– Test Case
* 전체 데이터 중 특정 값과 일치하는 레코드를 조회 ( == 조회)
* 전체 데이터 중 특정 값을 포함하는 레코드를 조회 (Like 조회)
* 전체 데이터의 레코드 건수 조회 (Count 조회)
Test Log 데이터를 HDFS에 넣어서 Hive의 External Table을 이용했기 때문에 RDBMS와의 비교는 무의미 하지만
인덱스 없는 테이블을 풀스캔 하는 정도의 성능을 생각하시면서 보시면 될 것 같습니다.
2. 1차 성능 테스트 결과
1차로 ( Master NameNode*1 + DataNode*1) replica 1 4,897,086,143 bytes ( 9,291,682 rows)의 데이터로 환경을 구축하여 성능을 테스트 한 결과 입니다.
| ( Master NameNode*1 + DataNode*1) replica 1 4,897,086,143 bytes ( 9,291,682 rows)의 데이터 | (단위:초) | ||||||||||||
| 횟수 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Min | Max | Avg |
| == 조회 | 52.116 | 53.429 | 53.763 | 53.845 | 52.731 | 52.742 | 52.741 | 54.815 | 52.813 | 52.74 | 52.116 | 54.815 | 53.22216667 |
| Like 조회 | 59.201 | 59.488 | 57.812 | 57.857 | 57.948 | 57.906 | 57.852 | 56.808 | 58.857 | 56.813 | 56.808 | 59.488 | 58.06983333 |
| Count 조회 | 46.847 | 47.958 | 47.639 | 47.62 | 46.616 | 47.573 | 47.622 | 47.6 | 46.717 | 47.678 | 46.616 | 47.958 | 47.37033333 |
보시다시피 RDBMS에 비해서는 형편없는 성능을 보여줍니다. 이는 물론 Hive가 Query를 Compile해서 MapReduce로 변환하고 Hadoop과 통신하는 기본적인 프로세스가 시간을 잡아먹기 때문에 당연한 결과입니다.
데이터 노드도 1대이고 Replication도 의미없이 1이기 때문에 성능에 큰 기대를 거는 것 자체가 의미없어 보입니다.
3. 2차 성능 테스트 결과
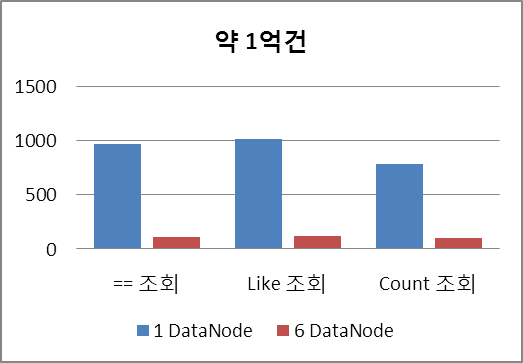
2차에서는 테스트 데이터를 더 늘려 ( Master NameNode*1 + DataNode*1) replica 1 53,867,947,573 bytes ( 102,208,502 rows)의 데이터로 환경을 구축하여 늘어난 데이터 량 만큼 얼마나 시간이 늘어나는지 측정해 보았습니다.
| ( Master NameNode*1 + DataNode*1) replica 1 53,867,947,573 bytes ( 102,208,502 rows)의 데이터 | (단위:초) | ||||||||||||
| 횟수 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Min | Max | Avg |
| == 조회 | 913.028 | 1041.087 | 926.712 | 943.803 | 913.028 | 1041.087 | 963.1241667 | ||||||
| Like 조회 | 1009.823 | 1028.858 | 1016.589 | 1004.376 | 1004.376 | 1028.858 | 1015.48 | ||||||
| Count 조회 | 763.897 | 785.919 | 805.001 | 792.915 | 763.897 | 805.001 | 786.105 | ||||||
10배 늘어난 데이터 량에 비해서 10배 이상의 시간이 소요됨을 알 수 있습니다. 시간이 너무 오래 걸려서 4번 씩 밖에 측정하지 못했습니다.
약 1억건의 데이터에 대해서 15분 이상이 걸리고 있습니다.
4. 3차 성능 테스트 결과
3차에서는 Hadoop 사용에 좀 더 의미가 있도록 DataNode를 더 늘려서
( Master NameNode*1 + DataNode*6) replica 3 4,897,086,143 bytes ( 9,291,682 rows)의 데이터로 구성하여
1차 환경과 비교할 수 있게 테스트 해 보았습니다.
| ( Master NameNode*1 + DataNode*6) replica 3 4,897,086,143 bytes ( 9,291,682 rows)의 데이터 | (단위:초) | ||||||||||||
| 횟수 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Min | Max | Avg |
| == 조회 | 18.212 | 18.035 | 17.973 | 17.965 | 17.899 | 17.746 | 16.865 | 17.729 | 18.663 | 18.681 | 16.865 | 18.681 | 17.94283333 |
| Like 조회 | 18.959 | 19.963 | 19.835 | 18.77 | 19.713 | 18.802 | 19.749 | 19.825 | 17.7 | 19.794 | 17.7 | 19.963 | 19.23108333 |
| Count 조회 | 21.688 | 21.855 | 21.714 | 21.626 | 20.696 | 20.741 | 21.637 | 21.47 | 22.485 | 21.554 | 20.696 | 22.485 | 21.55391667 |
1차 테스트에 비해 2배 이상 속도가 빨라 졌습니다. MapReduce의 진정한 파워는 여러 머신에 의한 병렬 처리에서 나오기 때문에 되도록 DataNode를 늘려주는게 중요합니다.
5. 4차 성능 테스트 결과
동일하게 2차 테스트와 비교 할 수 있게 데이터를 약 1억건으로 상향하여
( Master NameNode*1 + DataNode*6) replica 3 53,867,947,573 bytes ( 102,208,502 rows)의 데이터로 구성하여 테스트 해 본 결과입니다.
| ( Master NameNode*1 + DataNode*6) replica 3 53,867,947,573 bytes ( 102,208,502 rows)의 데이터 | (단위:초) | ||||||||||||
| 횟수 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Min | Max | Avg |
| == 조회 | 113.005 | 115.034 | 113.752 | 114.095 | 114.899 | 116.667 | 112.802 | 113.97 | 112.725 | 111.592 | 111.592 | 116.667 | 113.9 |
| Like 조회 | 125.129 | 125.016 | 122.211 | 124.293 | 123.199 | 122.931 | 125.153 | 124.294 | 124.355 | 124.29 | 122.211 | 125.153 | 124.0195833 |
| Count 조회 | 100.768 | 101.702 | 101.859 | 102.85 | 101.553 | 101.696 | 101.676 | 101.629 | 101.582 | 102.01 | 100.768 | 102.85 | 101.74525 |
DataNode가 1대 일 때에 비해서 8배 이상 좋은 성능을 내 주고 있습니다.
6. Hadoop 성능 튜닝
지금 까지는 Hadoop에 기본 설정만을 사용한 상태에서 측정한 성능 수치였습니다. Hadoop을 사용할 때에는 각 환경에 맞게 적절한 환경변수를 설정해서 사용해야 합니다.
구글신(?)께서 제공해주신 여러 Reference를 통해 아래와 같이 튜닝을 한 후 다시 테스트 해 보았습니다.
– conf/core-site.xml 수정
<property>
<name>fs.inmemory.size.mb</name>
<value>200</value>
</property>
<property>
<name>io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>io.sort.mb</name>
<value>500</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
– conf/hdfs-site.xml 수정
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>40</value>
</property> <property>
<name>tasktracker.http.threads</name>
<value>400</value>
</property>
– conf/mapred-site.xml 수정
<property>
<name>mapred.reduce.parallel.copies</name>
<value>20</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>16</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>16</value>
</property>
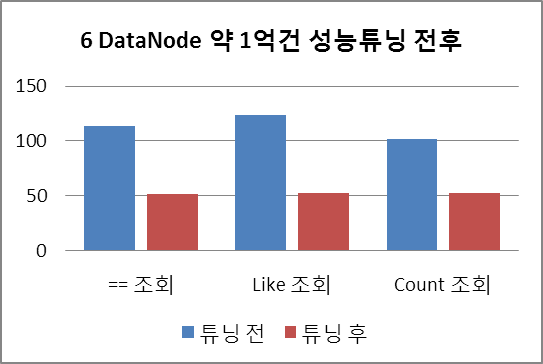
튜닝 이후 성능 테스트 결과는 아래와 같습니다.
| ( Master NameNode*1 + DataNode*6) replica 3 53,867,947,573 bytes ( 102,208,502 rows)의 데이터 성능 튜닝 후 | (단위:초) | ||||||||||||
| 횟수 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Min | Max | Avg |
| == 조회 | 55.886 | 52.54 | 53.504 | 49.253 | 49.385 | 52.516 | 52.278 | 48.152 | 50.344 | 51.239 | 48.152 | 55.886 | 51.59458333 |
| Like 조회 | 57.347 | 52.651 | 56.738 | 52.854 | 54.564 | 53.678 | 49.606 | 45.768 | 49.498 | 55.66 | 45.768 | 57.347 | 52.62325 |
| Count 조회 | 56.445 | 48.194 | 55.983 | 51.996 | 53.137 | 51.231 | 56.354 | 51.282 | 53.445 | 52.331 | 48.194 | 56.445 | 52.91975 |
4차 테스트와 비교하여 2배 이상 속도가 빨라졌음을 확일 할 수 있습니다.
자세한 성능 튜닝 포인트에 대해서는
Advanced Hadoop Tuning and Optimization – Hadoop Consulting 과 Hadoop Performance Tuning에서 확인 할 수 있으며,
가장 성능에 영향을 미쳤던 포인트는 mapred.tasktracker.map/reduce.tasks.maximum 값으로 TaskTracker에서 Map/Reduce의 최대 Task 설정값으로 기본값은 2입니다.
이 수치를 DataNode 서버 Core 수/2 ~ DataNode서버 Core 수*2 사이 값으로 설정하면 훨씬 좋은 성능을 느낄 수 있습니다.
 |
 |
 |
 |